Incremental refresh is a great feature in Power BI for Datasets and Dataflows, to greatly reduce refresh times and reduce the load on the source system. However, all the data/partitions are loaded at the same time at creation (and following changes). Usually, this works fine but timeouts/errors can occur with very large/complex data volumes. For datasets, a creator can partially load the partitions through the XMLA endpoint with SSMS, as demonstrated by Patrick Leblanc in this video. However, dataflows don't have an XMLA endpoint, so a workaround is needed.
Note: Although there is not a size limit on dataflows, creating a dataflow that struggles with the initial load is not recommended. The approach in this article is provided as a short-term mitigation until a more scaleable approach is implemented.
This approach requires a few things:
- Incremental refresh set up with Detect Changes selected (over all partitions)
- A simple query/table with values to inidicate if each partition should be fully loaded or not (an Excel file in this demo)
- A small amount of data (with the same columns) to be loaded in place of each partition until it is fully loaded
For this example, a table with over 33 million rows from an Azure SQL database in incrementaly loaded into a Dataflow, partitioned by year. The Dataflow loads just fine without this technique, but I used it for ease of demo. Also, I used a PPU workspace (so I could quickly check loaded data volumes with the Enhanced Compute Engine), but it should work with a Pro license in shared capacities too.
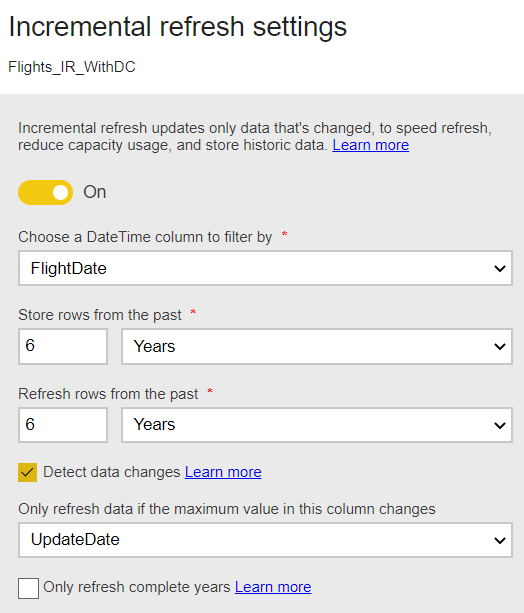
For #1, the pic below shows the Incremental Refresh settings. There are 5 1/2 years of flights data in the table, so 6 partitions are created. Note that detect data changes is selected. More on that and the "UpdateDate" column later.
A simple query was created with only a Choose Columns step, but more advanced queries are possible, so long as query folding is maintained (important for incremental refresh anyway). Once the incremental refresh is set up as above, the bottom three artifacts are automatically created.
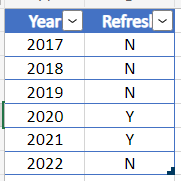
For #2, a simple Excel table stored on a SharePoint site can be used to provide the Y/N flag needed for each partition. A query to bring in this table is added to the Dataflow, with "Enable load" unchecked. This table is later filtered by RangeStart within each partition, using [Year] = Date.Year(RangeStart), to get the Y/N value for each partition. At the start, all the Refresh values would be set to N and incrementally set to Y to load one or a few partitions at a time. The final partition should be loaded last, as explained later.
For #3, a small amount of data with the same columns needs to be loaded into each partition when Refresh is set to N. I chose to create a hard-coded table as follows:
- Temporarily add a Keep Rows step to the query with only the top 6 rows (one for each partition)
- Select "Copy Table" and then paste the data into a new query with the "Enter data" button
- Manually update the values in the DateTime column filtered by RangeStart/RangeEnd, so that each partition will hold one row (when Refresh is set to "N").
- A custom column called "UpdateDate" is then added, which is the one used for Detect Changes. This same column is also added to the main query. Since a DateTime value is needed, an if…then…else is used to add either the RangeStart value (when Refresh = "N") or the RangeEnd value (when Refresh = "Y"). The last partition uses DateTime.LocalNow(), so that it changes with each refresh and therefore is re-loaded to get the latest data, as shown later.
- Note that using a hard-coded table means that no queries are sent to the source when a partition's Refresh value is "N".
At this point, the Power Query Online editor looks like this, with the added queries called RefreshTable and HardCodedTable.
The key now is to update the main query (Flights_IncLoad) to tie it all together. That query is shown below.
let
RefreshData = RefreshTable,
RefreshRecord = try Table.SelectRows(RefreshData, each [Year] = Date.Year(RangeStart)){0} otherwise [Year = 2099, Refresh = "N"],
IsLatestPartition =RangeStart <= DateTime.LocalNow() and RangeEnd > DateTime.LocalNow(),
Source = Sql.Database("abcsqlserver.database.windows.net", "Flights"),
Navigation = Source{[Schema = "dbo", Item = "Flights"]}[Data],
#"Added custom" = Table.TransformColumnTypes(Table.AddColumn(Navigation, "UpdateDate", each if RefreshRecord[Refresh] = "Y" then (if IsLatestPartition then DateTime.LocalNow() else RangeEnd) else RangeStart), {{"UpdateDate", type datetime}}),
Output = if RefreshRecord[Refresh] = "Y" then #"Added custom" else HardCodedTable,
#"Choose columns" = Table.SelectColumns(Output, {"FlightDate", "Reporting_Airline", "Tail_Number", "Flight_Number_Reporting_Airline", "Origin", "Dest", "CRSDepTime", "DepTime", "DepDelay", "TaxiOut", "WheelsOff", "WheelsOn", "TaxiIn", "CRSArrTime", "ArrTime", "ArrDelay", "Cancelled", "CancellationCode", "Diverted", "CRSElapsedTime", "ActualElapsedTime", "AirTime", "Flights", "Distance", "CarrierDelay", "WeatherDelay", "NASDelay", "SecurityDelay", "LateAircraftDelay", "UpdateDate"}),
#"Flights_IncLoad-466C6967687444617465-autogenerated_for_incremental_refresh" = Table.SelectRows(#"Choose columns", each DateTime.From([FlightDate]) >= RangeStart and DateTime.From([FlightDate]) < RangeEnd)
in
#"Flights_IncLoad-466C6967687444617465-autogenerated_for_incremental_refresh"The first two rows bring in the RefreshTable and create a record from the row for the year for that partition. The RangeStart and RangeEnd parameters are manually updated while editing to get a preview for a given year/partition. The IsLatestPartition step checks if the current partition is the most recent, which is used in the #"Added custom" step to set the "UpdateDate" column to RangeEnd or DateTime.LocalNow(), so that the latest partition is always re-loaded. The next steps are the original query, except for the Output step, which loads either the hard-coded data or the full partition based on the RefreshRecord[Refresh] value of "N" or "Y", respectively. The final filter step is automatically added when incremental refresh is enabled.
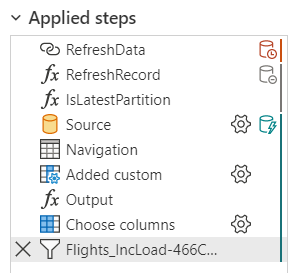
Shown below is the view of the Applied Steps window for a partition set to "Y" and RangeStart/RangeEnd set to 2020. It is critical that query folding is maintained through the last steps during the "Y" condition, not just for the efficient load of this partition, but so that the "_Canary" query successfuly folds the "select top 1" to check the max "UpdateDate" value.
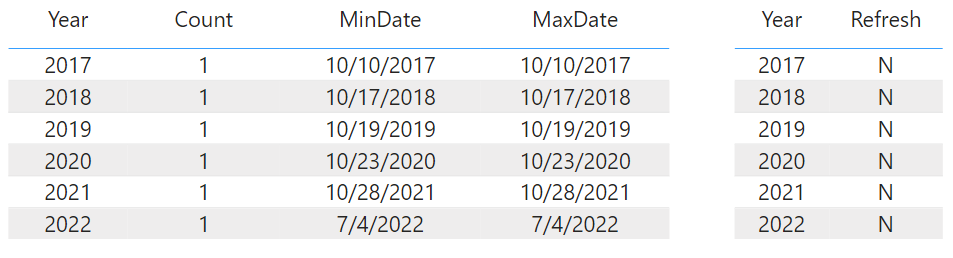
The value for 2020 is then set to "Y" and the Dataflow and report are refreshed. The Dataflow took 3.5 min to refresh (the full Dataflow loads in ~18 min). A profiler trace from Azure Data Studio was also running to show that queries were sent to the source for only the 2020 partition (one to load the data, and one to check the "UpdateDate" column added in the query).
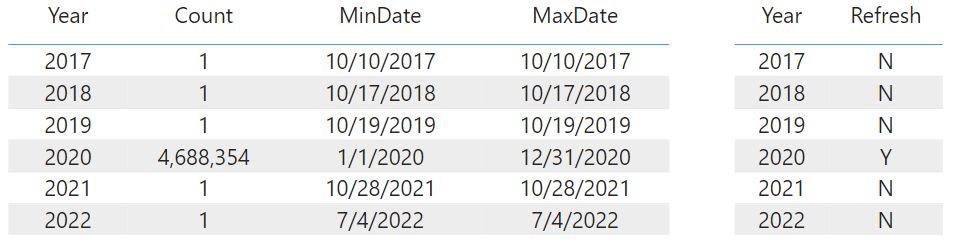

When 2021 is then set to "Y", the profiler traces shows the 2021 query and "select top 1" queries for both 2020 and 2021. Since the value for 2020 is not changed (still RangeEnd), it is not re-loaded.
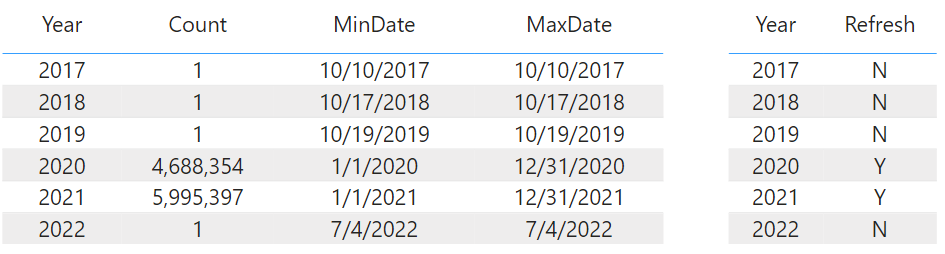

The other partitions can then be loaded. Finally, the last partition is loaded. Since the "UpdateDate" value for it is set to DateTime.LocalNow(), it is always reloaded. In this demo, only the last 3 partitions are loaded, so more "select top 1" queries would be seen if all partitions had been previously loaded before the final.
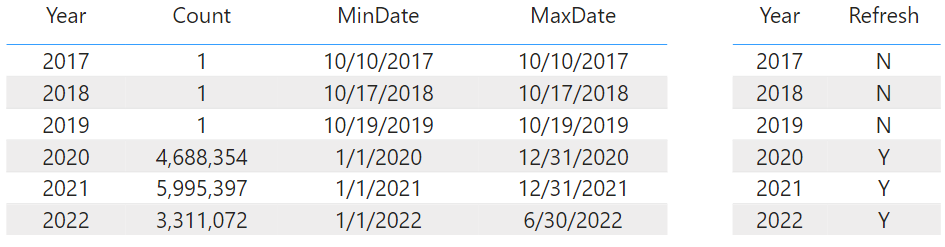

Since this technique hijacks the Detect Changes functionality, you can no longer do that in the other partitions. However, it is possible to unload a partition by putting the Refresh value back to "N", so that it can then be re-loaded if known data changes have occured.
